




- What does a thread in Python mean?
- How are Python multithreading and multiprocessing related?
- Let’s Get Started
- Next Example Featuring Concurrency and Parallelism in Python
- Another Example Featuring Concurrency and Parallelism in Python
- Python Multithreading vs. Multiprocessing
Share It On:



Multithreading is a core concept of software programming wherein software creates multiple threads having execution cycling. Several processors can use the single set of code at different coding stages. In software programming, a thread is the smallest unit of execution.
What does a thread in Python mean?
In software programming, a thread is a task. The thread offers a way to programmers to add concurrency to the programs. A process or a task can execute multiple threads at a time known as multi-threading.
How are Python multithreading and multiprocessing related?
With the help of Python multithreading and multiprocessing, Python code can run concurrently. With the help of multiprocessing, codes can be made parallel.
Python is just like any other programming language that has features and functionalities that any developer would love to embrace. However, the programing language does see a lot of criticism on the grounds of the fact that it is difficult to use Python for multithreaded work.
Such discussions generally point the finger at the global interpreter lock or GIL. Global interpreter lock inhibits multiple threads of Python code from running simultaneously. With this reason, the Python multithreading module sometimes behaves unexpectedly for developers who do not have much information on Python. If interested in how logging from Python apps looks, check this page.
Developers typically from Java or C++ background face many difficulties while choosing the same. However, Python gives the advantage of writing the codes that are running concurrently or in parallel to make a significant difference in the resulting performance. However, developers need to take care of certain things.
This Python concurrency guide will feature a small Python script to allow downloading of famous images from Imgur (the online image-sharing community). I will start with a version that downloads image one at a time. For initiating, it is vital to have a registered app on Imgur. In case, you have one, it’s great. In case, you lack such an app, create one and come along.
Let’s Get Started
I will be creating a Python module first, called download.py. This file will have all the prerequisites to fetch the list of images and to download the same. Let’s separate these functionalities into different functions as stated here.
- get_links
- download_link
- setup_download_dir
I will use the third functionality setup_download_dir to create a download destination directory in case there is none.
Imgur’s API needs HTTP requests to take the Authorization header with the client ID. One can get this client ID from the dashboard of the application that was just registered on Imgur, and the response will be JSON encoded.
Here Python’s standard JSON library can be used to decode it. Now, it comes to downloading, and all that it requires is to fetch the image by its URL and write it to a file.
Here is the blueprint of the script
import json
import logging
import os
from pathlib import Path
from urllib.request import urlopen, Request
logger = logging.getLogger(__name__)
def get_links(client_id):
headers = {'Authorization': 'Client-ID {}'.format(client_id)}
req = Request('https://api.imgur.com/3/gallery/', headers=headers, method='GET')
with urlopen(req) as resp:
data = json.loads(resp.readall().decode('utf-8'))
return map(lambda item: item['link'], data['data'])
def download_link(directory, link):
logger.info('Downloading %s', link)
download_path = directory / os.path.basename(link)
with urlopen(link) as image, download_path.open('wb') as f:
f.write(image.readall())
def setup_download_dir():
download_dir = Path('images')
if not download_dir.exists():
download_dir.mkdir()
return download_dir
Now, it is the time to create a module having functions to download the images one after another. Let’s name it single.py. It will include the primary function of the first version of the Imgur image downloader. The environment variable IMGUR_CLIENT_ID will have retrieved the Imgur client ID. It will start the setup_download_dir to create a download directory.
At last, the list will fetch the images using the function get_links. It will also filter out all the GIFs and other album URLs. Now, use download_link to download and save the images. Here is how a single.py looks like:
import logging
import os
from time import time
from download import setup_download_dir, get_links, download_link
logging.basicConfig(level=logging.DEBUG, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logging.getLogger('requests').setLevel(logging.CRITICAL)
logger = logging.getLogger(__name__)
def main():
ts = time()
client_id = os.getenv('IMGUR_CLIENT_ID')
if not client_id:
raise Exception("Couldn't find IMGUR_CLIENT_ID environment variable!")
download_dir = setup_download_dir()
links = [l for l in get_links(client_id) if l.endswith('.jpg')]
for link in links:
download_link(download_dir, link)
print('Took {}s'.format(time() - ts))
if __name__ == '__main__':
main()
The timings and the number of downloads used may vary depending upon the speed of a system. The rate of the downloads can be increased by introducing concurrency or parallelism. It will help to speed up the entire download time.
For developer’s convenience, all of these Python scripts can be found in this GitHub repository.
Now, let’s get into a threading example: Concurrency and Parallelism in Python
With the help of threading a Python developer can quickly achieve Python concurrency and parallelism. The operating system most commonly provides threading. Threads are lighter if compared with processors and have the same memory space.
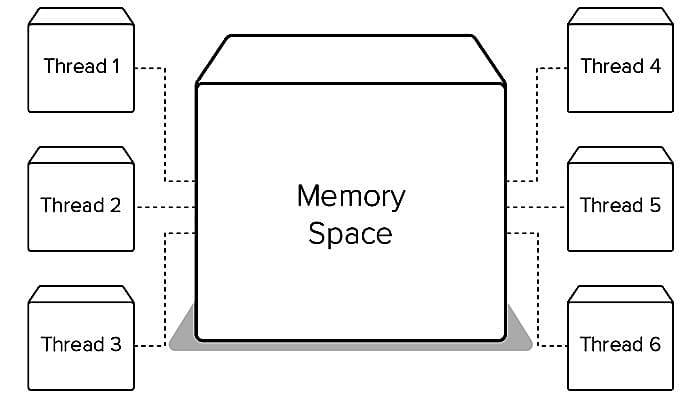
I will now write a new module to replace single.py in this Python threading example. The new module will have a pool of eight new threads plus the main thread, and thus the new count will be nine threads. One can decide on the specific number of threads to produce.
The new code is almost the same as the previous one with an exception that there is a new class DownloadWorker. It is a descendant of the Python Thread class. On every iteration, the class calls self.queue.get() to fetch a URL to form a thread-safe queue.
It won’t proceed until there is an item in the queue to process. Once an item from the queue is received, it then calls the same download_link method. (the script that was used in the previous script to download the image to the images directory). Once the download gets over, the worker signals the queue for finishing the task.
The queue has the track of how many tasks were enqueued. When you call the queue.join() it would block the main thread. The thread would be blocked entirely forever if workers fail to signal when the task has been completed.
from queue import Queue
from threading import Thread
class DownloadWorker(Thread):
def __init__(self, queue):
Thread.__init__(self)
self.queue = queue
def run(self):
while True:
# Get the work from the queue and expand the tuple
directory, link = self.queue.get()
download_link(directory, link)
self.queue.task_done()
def main():
ts = time()
client_id = os.getenv('IMGUR_CLIENT_ID')
if not client_id:
raise Exception("Couldn't find IMGUR_CLIENT_ID environment variable!")
download_dir = setup_download_dir()
links = [l for l in get_links(client_id) if l.endswith('.jpg')]
# Create a queue to communicate with the worker threads
queue = Queue()
# Create 8 worker threads
for x in range(8):
worker = DownloadWorker(queue)
# Setting daemon to True will let the main thread exit even though the workers are blocking
worker.daemon = True
worker.start()
# Put the tasks into the queue as a tuple
for link in links:
logger.info('Queueing {}'.format(link))
queue.put((download_dir, link))
# Causes the main thread to wait for the queue to finish processing all the tasks
queue.join()
print('Took {}'.format(time() - ts))
It is worth mentioning that GIL is the reason because of which one thread was executing at a time throughout the process. And that makes the code concurrent and not parallel. And being an IO-bound task, the code will run fast.
The process will help to download the image quickly also depending upon the type of network you use. It is the reason Python multithreading can provide a massive speed increase. Also, the process can switch between the threads whenever one of them is ready to do some work.
The downside of using the Python threading module or any other interpreted language taking support from GIL may result in performance reduction. In case, the performing code is a CPU bound task like decompressing gzip files, including the threading module will slower the execution time.
Well, one can use the multiprocessing module for executing the CPU bound task for real parallel execution.
While the other reference Python implementation—CPython–has a GIL, but that won’t seem fit to all the Python implementation. For instance, IronPython, a Python implementation using the .NET framework lacks a GIL, and Jython as well, which is Java-based implementation. You can find a list of working Python implementations here.
Next Example Featuring Concurrency and Parallelism in Python
The multiprocessing module is more accessible if compared with the threading module, the reason being there is no need to add a class like the Python threading example. The only changes that the primary function needs are:
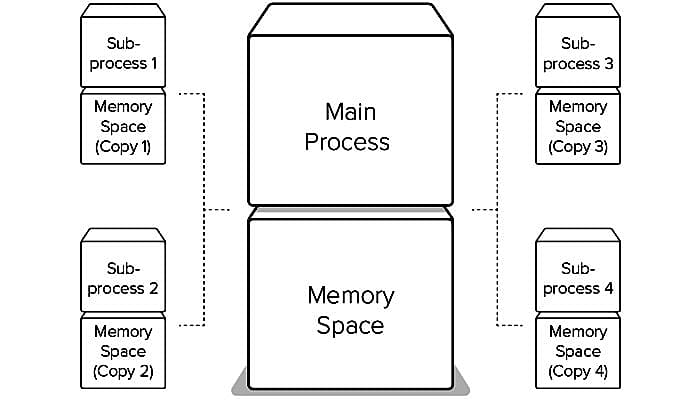
The multiprocessing Pool. is created to multiple processes. The map method will help to pass the list of URLs to the pool. As a result, it will produce eight new processes and use each one to download the images in parallel.
This is an example of parallelism, but it has an additional hidden cost along with it. The complete memory of the script is copied into each subprocess that is additionally produced. This is not a big deal. However, it can create a few issues for the developers.
from functools import partial
from multiprocessing.pool import Pool
def main():
ts = time()
client_id = os.getenv('IMGUR_CLIENT_ID')
if not client_id:
raise Exception("Couldn't find IMGUR_CLIENT_ID environment variable!")
download_dir = setup_download_dir()
links = [l for l in get_links(client_id) if l.endswith('.jpg')]
download = partial(download_link, download_dir)
with Pool(8) as p:
p.map(download, links)
print('Took {}s'.format(time() - ts))
Another Example Featuring Concurrency and Parallelism in Python
Threading and multiprocessing modules are great for scripts, but the fact that you are running the same on your personal computer can’t be ignored. What in case if the entire work to be done on a different machine?
What if you need to scale up to more than the CPU the machine can handle? A solution to this typical problem can be long-running back-end tasks for web applications. Running and spinning the bunch of threads on the same machine may degrade the performance of your app for the users, which is not at all an acceptable case.
Therefore, it is a great idea to run the codes on another machine. For the same, you can take the help of an awesome Python library RQ. It’s a great library having functional codes for the users.
Using the library users can enqueue a function and its arguments. This adds the function call representation. The functions are then appended to a Redis list. The very first job here is to enqueue the first step and we will require at least one worker for the same.
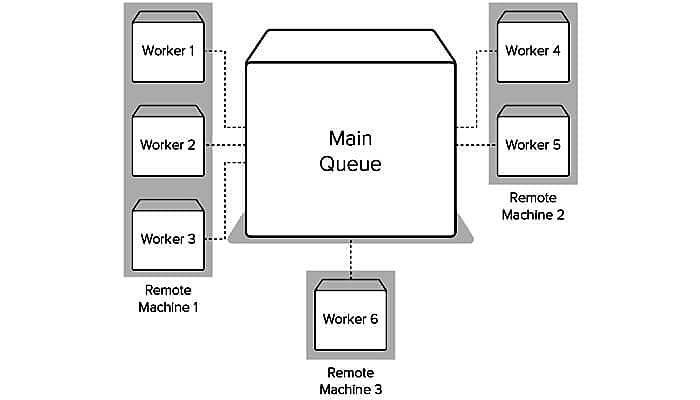
Another job here is not only to install but also to run a Redis server on the system. And for the same get the access to a running Redis server. After that, we need to make some small changes to the existing code.
The prerequisite is to create a series of RQ queue to pass it an instance of a Redis server from the Redis-py library. Then, instead of just calling the download_link method, we call q.enqueue(download_link, download_dir, link). When the job is executed entirely, the arguments or the keyword arguments will be passed along easily.
The last step needed here is to initiate some workers. The RQ will become handy for you to provide the script to run workers on the default queue. You need to run rqworker in a terminal window, and it will automatically start a worker listening on the default queue.
Ensure your scripts reside in the current working directory. Now run rqworker queue_name, and it will listen to that named queue. A great thing associated with RQ is you can run as many workers as you like on as many different machines as you like as long as you can connect to Redis. It makes it easy to scale up as the given application grows. Here is the source to get the RQ version:
from redis import Redis
from rq import Queue
def main():
client_id = os.getenv('IMGUR_CLIENT_ID')
if not client_id:
raise Exception("Couldn't find IMGUR_CLIENT_ID environment variable!")
download_dir = setup_download_dir()
links = [l for l in get_links(client_id) if l.endswith('.jpg')]
q = Queue(connection=Redis(host='localhost', port=6379))
for link in links:
q.enqueue(download_link, download_dir, link)
There are other Python job queue solutions available. However, we have used RQ as it is easy to use.
Also Read: How to Enumerate in Python
Python Multithreading vs. Multiprocessing
For the codes having IO bound, both the processes including multiprocessing and multithreading in Python will work. Multiprocessing, as explained earlier, makes it easy to drop in threading but the downside associated is it has a higher memory overhead.
In case the code is CPU bound, multiprocessing will seem a better choice. The instances when RQ is going to work better include scaling the work across multiple machines when web apps are in use.
Python concurrent.futures
We have not talked about Python concurrent.futures in the article here and the packages it offers along. The package is just useful when it is about using concurrency and parallelism with Python. The mentions in the article include that the Python multiprocessing module seems easier to drop into existing code than the threading module.
It was mentioned because Python 3 threading module needed the subclassing Thread class along with creating a Queue for the threads to monitor the work.
The execution goes like:
import logging
import os
from concurrent.futures import ThreadPoolExecutor
from functools import partial
from time import time
from download import setup_download_dir, get_links, download_link
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
def main():
client_id = os.getenv('IMGUR_CLIENT_ID')
if not client_id:
raise Exception("Couldn't find IMGUR_CLIENT_ID environment variable!")
download_dir = setup_download_dir()
links = get_links(client_id)
# By placing the executor inside a with block, the executors shutdown method
# will be called cleaning up threads.
#
# By default, the executor sets number of workers to 5 times the number of
# CPUs.
with ThreadPoolExecutor() as executor:
# Create a new partially applied function that stores the directory
# argument.
#
# This allows the download_link function that normally takes two
# arguments to work with the map function that expects a function of a
# single argument.
fn = partial(download_link, download_dir)
# Executes fn concurrently using threads on the links iterable. The
# timeout is for the entire process, not a single call, so downloading
# all images must complete within 30 seconds.
executor.map(fn, links, timeout=30)
if __name__ == '__main__':
main()
Now that we have all the required images with us downloaded with the Python ThreadPoolExecutor, we’ll now initiate to test the CPU-bound task.
It depends whether you wish to develop the thumbnail versions of all the images in both a single-threaded, single-process script to test the multiprocessing-based solution. For resizing the image use Pillow library.
The initial script goes as:
import logging
from pathlib import Path
from time import time
from PIL import Image
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
def create_thumbnail(size, path):
"""
Creates a thumbnail of an image with the same name as image but with
_thumbnail appended before the extension. E.g.:
>>> create_thumbnail((128, 128), 'image.jpg')
A new thumbnail image is created with the name image_thumbnail.jpg
:param size: A tuple of the width and height of the image
:param path: The path to the image file
:return: None
"""
image = Image.open(path)
image.thumbnail(size)
path = Path(path)
name = path.stem + '_thumbnail' + path.suffix
thumbnail_path = path.with_name(name)
image.save(thumbnail_path)
def main():
ts = time()
for image_path in Path('images').iterdir():
create_thumbnail((128, 128), image_path)
logging.info('Took %s', time() - ts)
if __name__ == '__main__':
main()
The scripts call for iteration under the images folder, and for the paths, it runs a “create_thumbnail” function is created.
This is an example on how functions use the pillow to open images along with creating a thumbnail and saving the new, smaller images having a similar name as the original but with an additional _thumbnail appended to the name.
Let’s see if we can speed up the time it takes to run the script on images.
import logging
from pathlib import Path
from time import time
from functools import partial
from concurrent.futures import ProcessPoolExecutor
from PIL import Image
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)
def create_thumbnail(size, path):
"""
Creates a thumbnail of an image with the same name as image but with
_thumbnail appended before the extension. E.g.:
>>> create_thumbnail((128, 128), 'image.jpg')
A new thumbnail image is created with the name image_thumbnail.jpg
:param size: A tuple of the width and height of the image
:param path: The path to the image file
:return: None
"""
path = Path(path)
name = path.stem + '_thumbnail' + path.suffix
thumbnail_path = path.with_name(name)
image = Image.open(path)
image.thumbnail(size)
image.save(thumbnail_path)
def main():
ts = time()
# Partially apply the create_thumbnail method, setting the size to 128x128
# and returning a function of a single argument.
thumbnail_128 = partial(create_thumbnail, (128, 128))
# Create the executor in a with block so shutdown is called when the block
# is exited.
with ProcessPoolExecutor() as executor:
executor.map(thumbnail_128, Path('images').iterdir())
logging.info('Took %s', time() - ts)
if __name__ == '__main__':
main()
The given method is identical to the last script. And the point of difference lies in developing ProcessPoolExecutor. We took the help from the executor’s map method to create the thumbnails in parallel. By default, a subprocess is created by the ProcessPoolExecutor one subprocess per CPU.
It is all on the Python multithreading and multiprocessing!
Read More About:
- React Vs. Angular: In-Depth Comparison
- Symfony Vs Laravel: The Debate Is Over Now
- Swift Vs. Kotlin: Similarities And Differences
- 10 Cardinal Mobile App Testing Phases
- How Cloud Technology Helping App Development World?


Sr. Content Strategist
Meet Manish Chandra Srivastava, the Strategic Content Architect & Marketing Guru who turns brands into legends. Armed with a Masters in Mass Communication (2015-17), Manish has dazzled giants like Collegedunia, Embibe, and Archies. His work is spotlighted on Hackernoon, Gamasutra, and Elearning Industry.
Beyond the writer’s block, Manish is often found distracted by movies, video games, AI, and other such nerdy stuff. But the point remains, If you need your brand to shine, Manish is who you need.





